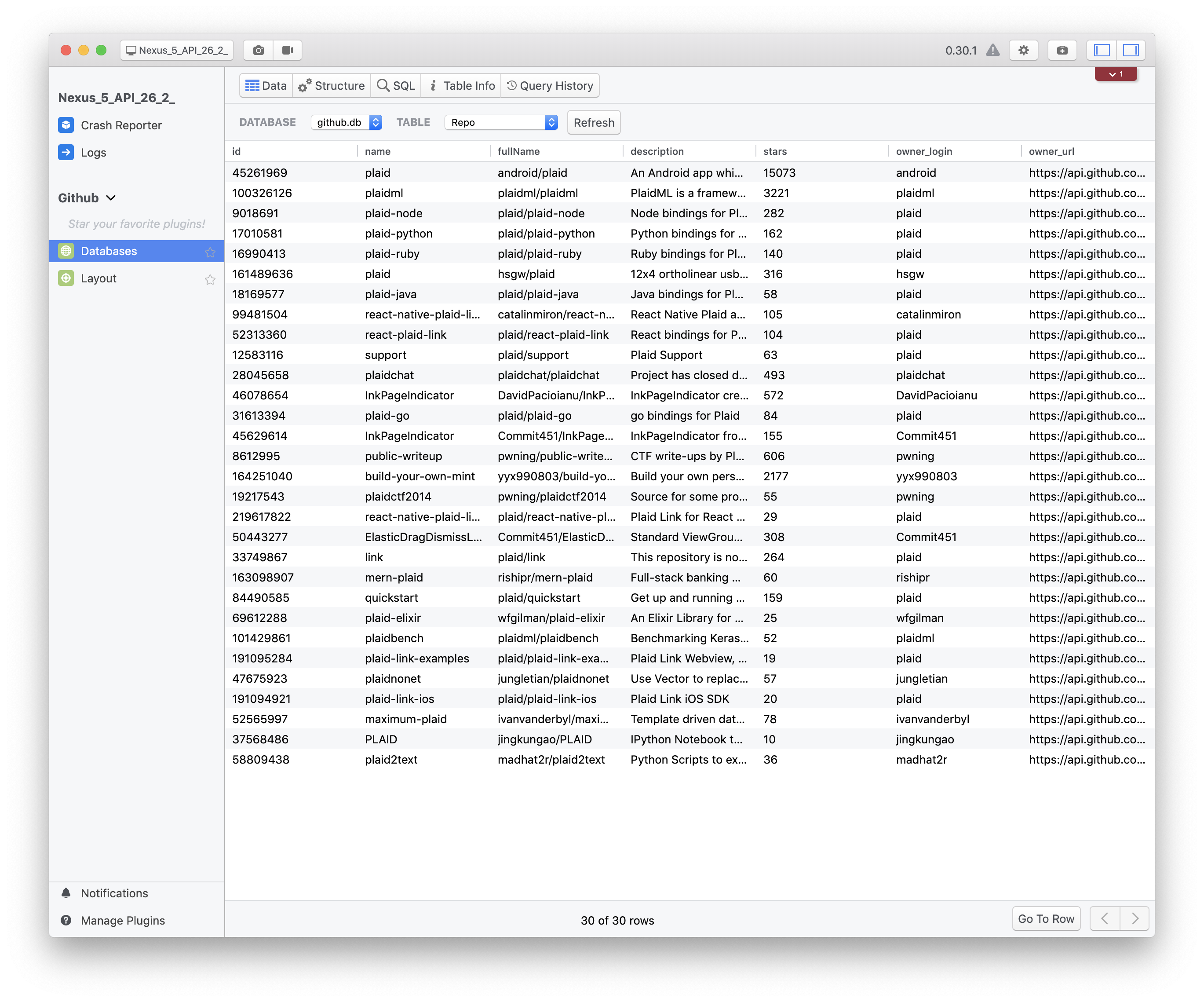
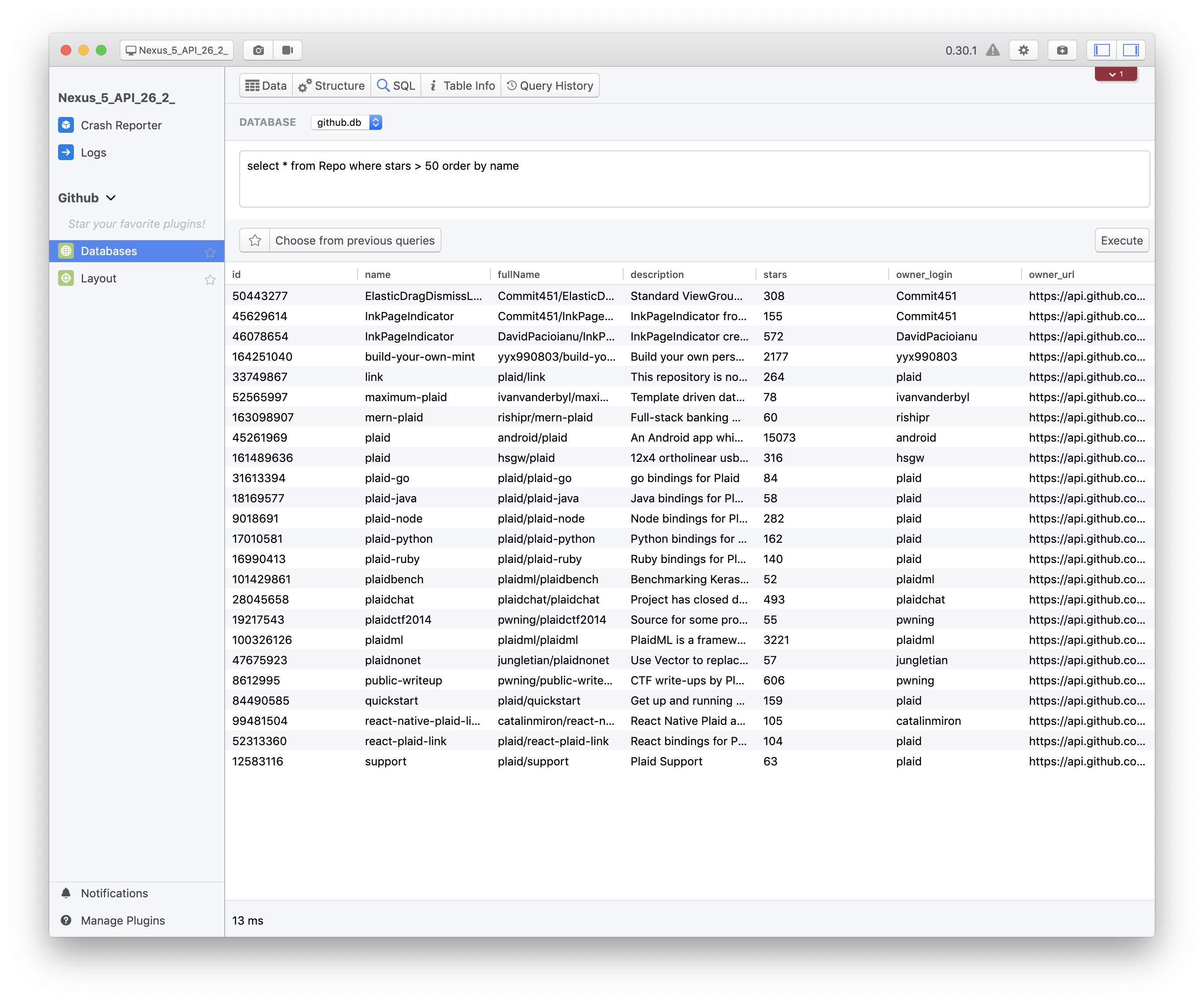
However, there are often times that you’ll need a tool more specific to your own workflow that Android Studio doesn’t provide, and that’s exactly where Flipper’s extensibility really shines. As an example, I’d like to go through building a custom plugin for Flipper, similar to one that I’ve used on my own projects, that demonstrates how easy it is to get started building these tools.
The Problem
As most apps grow, there becomes a need to measure app usage and engagement to better understand user behavior. In order to measure that, we often turn to analytics libraries (like Firebase Analytics) to handle this in-app behavior reporting. However, when implementing these client events, it’s often helpful to have a quick feedback loop to ensure that the event and associated payload are correct, without having to check an analytics dashboard (which can often take some time to refresh).
Luckily, most analytics libraries (including Firebase) have different solutions for this problem. In the Firebase Analytics library, the recommended debugging method is to set a property with ADB to log all the events to logcat. This does provide much faster feedback than checking a dashboard, but it’s not the most user friendly – developers need to set the property at the command line, and need to be monitoring logcat for all of the events (and also doesn’t offer much of a search/filter function).
The Solution
Rather than sticking to plain text in logcat, we can build a custom Flipper plugin that will display our analytics events in a filterable table. Most Flipper plugins are comprised of two parts – a client library that runs as part of your Android app, and a desktop plugin that runs inside Flipper for processing and displaying the data sent by the client.
All of the code for this example can be found in this example Github Repository.
Part 1: Client Side
On the Android side, you’ll need to add the Flipper SDK if you haven’t already. If you have Flipper set up already, you can skip to the next section. If not, here’s a quick run-down:
Add Flipper
Add the Gradle dependencies:
1 2 3 4 5 6 | |
Configure your Application class:
1 2 3 4 5 6 7 8 9 10 11 12 | |
Building the Plugin
And now it’s time to build the plugin! Create a class to hold your plugin logic (For this example, I will call mine AnalyticsPlugin). For the purposes of this sample, it’ll be a singleton object for reasons that we’ll see later.
We’ll subclass the BufferingFlipperPlugin class, rather than FlipperPlugin, because the bufffering version will keep our events in a buffer until the connection is made with the desktop client (so that we don’t lose any events).
We need to override getId(), which is how Flipper will correlate our client plugin with the matching desktop plugin, and runInBackground() in order to tell Flipper to keep communicating with the desktop client, even if our plugin isn’t the currently in the foreground.
Lastly, we’re going to create a reportEvent method, which will send whatever data we want to the server. In this example, we’ll send a unique identifier for the event, the event name, and the timestamp that the event occured at. Note: FlipperObject can even be constructed by using JSON text or a JSONObject!
Here’s what our plugin might look like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
After we create our plugin, we’ll need to go back to our Application class to install our plugin, just like we would with the pre-loaded ones:
1 2 3 4 | |
The last thing we need to do is actually call our plugin somewhere. The implementation of this part will depend a lot on the particular implementation of your own app, but for this example we’ll have an Analytics class that conditionally logs our events to Flipper in debug builds, and would do some normal production logic otherwise.
1 2 3 4 5 6 7 8 9 10 11 12 | |
Once that’s all done, the client work is complete!
Part 2: Desktop Side
Setup
In order to build the desktop-side plugin, we’ll need to set up our environment. We’ll need something called npx, which is a tool to execute Javascript packages. npx can be installed from Homebrew with brew install npx.
Once npx is installed, run the following command in the directory that you’d like to create your plugin in:
1
| |
This command will kick off a little bit of a “new plugin wizard”, asking a few questions about the plugin we’ll be creating:
- Whether the plugin is a “client” plugin or a “device” plugin – our plugin will require our app to communicate, we’ll choose
client. (Flipper also supportsdeviceplugins that don’t need any particular app to be running. For example, Logcat provides logs for the entire device, rather than needing any individual app). - An ID. This needs to be the same as the ID we specified in the client code, otherwise Flipper will have no way of matching up the two halves of our plugin.
- A title. This is the human readable name of the plugin that will show up in the sidebar.
After that, you should be able to cd into the newly created module directory and run yarn watch to have the plugin continuously be compiled when you make changes.
Building the Plugin
If you’re familiar with JavaScript and React (I’m not especially), creating the desktop side of the plugin might be easy. However, if you’re not experienced with these tools, Flipper includes some very convenient helpers for building a simple table UI. In this example, that’s exactly what we’ll be doing – let’s get started!
The init command we ran earlier auto-generated some files, one of which is index.tsx inside the src directory. Majority of the changes we’ll need to make will be in this file.
For our table, the first thing we’ll need to define is the fields that will be shown in each row:
1 2 3 4 5 | |
The next thing we need to do is create something called a DataTableColumn, which tells Flipper how to display our data. Each object defined in this section will map to the columns in our table – we can optionally provide a title to provide a more meaningful label at the top of the table and a width in either pixels, percent or nothing (which will distribute the space evenly).
1 2 3 4 5 6 7 8 9 10 | |
Lastly, we will use the Flipper createTablePlugin function to glue this all together:
1 2 3 4 5 6 | |
If a simple table is not what you’re looking for, there’s an entire section in the documentation about how to build a custom UI, and even how to write tests for the display logic.
After you have finished with this part, you should be able to open Flipper and see your plugin listed in the “Unavailable Plugins” display of the Flipper desktop app. Our plugin is considered “Unavailable” because no currently running application is available to connect to it…yet.

Build and launch your Android app and the plugin should now become “Disabled”.

We can now click “+” on the plugin row to “enable” it and start sending those analytics events – They should start showing up in the Flipper UI immediately!

Depending on your use-case, your events might not just be a simple string and timestamp. You’ll likely have defined some attributes, maybe the ID of an item being viewed, or the level number completed in a game. It would be great if there was a simple way to see all the data that corresponds to an event, right? Conveniently, the Flipper sidebar to show us that information in an easy to read way. All you need to do is click on the row, and a side panel will appear that renders our event as as JSON tree (I added some additional fields as a demo here):

Wrap up
By using the table plugin on the desktop side, searching and filtering behavior all comes for free, which is amazing if your app sends a lot of analytics events!
The code for both the Desktop Plugin and the Android sample app can be found on Github here.
As this post demonstrates – the Flipper SDK is pretty flexible and allows you to build all sorts of custom development tools to help ease everday tasks. Come up with an idea for a cool plugin? Send me a tweet, I’d love to hear about it!
(Thanks to Zarah for the editing and feedback for this post!)
]]>